汎用データフォーマット¶
目次
システムで扱う多様なデータ形式に対応した汎用の入出力ライブラリ機能を提供する。
本機能の大まかな構成は以下のとおり。
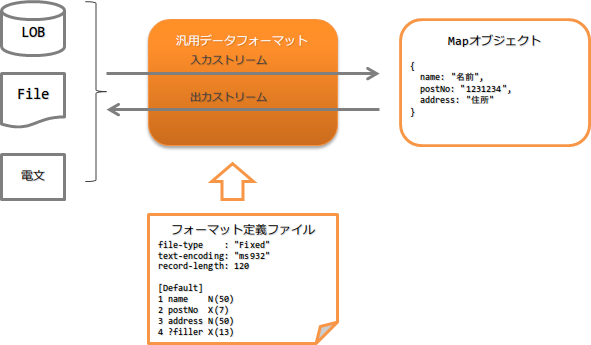
機能概要¶
標準でサポートするフォーマットが豊富¶
標準では、以下の形式のフォーマットに対応している。
固定長と可変長のデータ形式では、レコード毎にレイアウトの異なるマルチレイアウトデータにも対応している。 (XMLとJSONには、レコードという概念が存在しない。)
- 固定長
- 可変長(csvやtsvなど)
- JSON
- XML
重要
本機能には、以下のデメリットがある。
複雑な フォーマット定義ファイル を作成する必要がある。
入出力が Map に限定されており、実装誤りを起こしやすい。
- フィールド名を文字列で指定する必要があり、IDEの補完も使えないなど、実装時にミスを起こしやすい。
- アプリケーション側で、Mapから取り出した値をダウンキャストする必要がある。(誤ると、実行時に例外が送出される。)
データとJavaオブジェクトのマッピングに BeanUtil を使用していないため、他の機能とはマッピング方法が異なる。
出力対象の Map の扱い方がフォーマットによって異なる。このため、同じデータを複数のフォーマットに対応させる機能を使用した場合に、フォーマットによっては例外が発生するなど正常に動作しない場合がある。
例えば、下のケースで問題がある。
- XMLとJSONで必須項目にnullを指定した場合:
- XML:値を空文字として出力
- JSON:必須の例外を送出
出力対象のデータによってはJSONの仕様を満たせない場合がある。
例えば、 数値型 や 真偽値型 を使用し、出力対象のデータ型がこれらの型に対応していない場合に不正なJSONが出力される。
例:数値型を指定し、出力対象が「data」などの文字列の場合、{“number”:data}のような不正なJSONが出力される。
データ形式によって使用できる データタイプ の実装クラスが異なるため拡張しづらい。また、この設定の誤りは実行時まで検知できない。
このため原則本機能はやむを得ない場合を除き非推奨とする。 なお、 メッセージング編 は、内部で本機能を使用しているため、代替機能を使用できない。
- 本機能の代替機能
固定長: データバインド を使用すること。 可変長: データバインド を使用すること。 XML: Jakarta XML Binding を推奨する。 JSON: OSSの使用を推奨する。例えば、 Jackson(外部サイト、英語) が広く使われている。
様々な文字セットや文字種、データ形式に対応¶
文字列や10進数数値だけでなく、ホストでよく扱われるパック数値やゾーン10進数形式などに対応している。 また、UTF-8やShift_JISだけではなくEBCDICなどの文字セットにも対応している。
補足
文字セットについては、実行環境のJVMでサポートされているものが使用できる。
パディングやトリミングなどの変換処理に対応¶
固定長ファイルで多く使用されるスペースやゼロ(0)パディング及びトリミングに対応している。 このため、アプリケーション側でパディング処理やトリミング処理を行わなくて良い。
パディングやトリミングの詳細は、 フィールドコンバータ一覧 を参照。
モジュール一覧¶
- アップロードヘルパー を使用する場合は、
nablarch-fw-web-extensionを追加する。 - ファイルダウンロード を使用する場合は、
nablarch-fw-web-extensionを追加する。
<!-- 汎用データフォーマット -->
<dependency>
<groupId>com.nablarch.framework</groupId>
<artifactId>nablarch-core-dataformat</artifactId>
</dependency>
<!--
アップロードヘルパーを使用する場合、ダウンロードを使用する場合は以下を追加する
-->
<dependency>
<groupId>com.nablarch.framework</groupId>
<artifactId>nablarch-fw-web-extension</artifactId>
</dependency>
使用方法¶
入出力データのフォーマットを定義する¶
入出力対象データのフォーマット定義は、フォーマット定義ファイルに行う。
フォーマット定義ファイルは、以下のようなテキストファイル形式で作成する。 詳細な仕様は、 フォーマット定義ファイルの記述ルール を参照。
file-type: "Variable" # 可変長
text-encoding: "MS932" # 文字列型フィールドの文字エンコーディング
record-separator: "\r\n" # 改行コード(crlf)
field-separator: "," # csv
# レコード識別フィールドの定義
[Classifier]
1 dataKbn X # 1つめのフィールド
3 type X # 3つめのフィールド
[parentData]
dataKbn = "1"
type = "01"
1 dataKbn X
2 ?filler X
3 type X
4 data X
[childData]
dataKbn = "1"
type = "02"
1 dataKbn X
2 ?filler X
3 type X
4 data X
ファイルにデータを出力する¶
データレコードの内容をファイルに出力する方法について説明する。
ファイルへのデータ出力は、 FileRecordWriterHolder を使用することで実現できる。
以下に実装例を示す。
- ポイント
- ファイルに書き込むデータは Map として準備する。
- Map のキー値は、 入出力データのフォーマットを定義する で定義したフィールド名を設定する。(大文字、小文字は区別しない)
- FileRecordWriterHolder の open メソッドを呼び出して、ファイルリソースを書き込み可能状態にする。
- FileRecordWriterHolder の write メソッドを呼び出して、データをファイルに書き込む。
// 書き込み対象のデータ
Map<String, Object> user = new HashMap<>();
user.put("name", "名前");
user.put("age", 20);
// 書き込み対象のファイルを開く
FileRecordWriterHolder.open("users.csv", "user_csv_format");
// データを書き込む
FileRecordWriterHolder.write(user, "user.csv");
補足
FileRecordWriterHolder を使用するためには、 フォーマット定義ファイル の配置ディレクトリや出力先ディレクトリを ファイルパス管理 に設定する必要がある。
必要となるディレクトリの設定値については、 FileRecordWriterHolder を参照。
重要
FileRecordWriterHolder で開いたファイルリソースは、 出力ファイル開放ハンドラ にて自動的に開放される。 このため、 FileRecordWriterHolder を使用する場合には、 必ず 出力ファイル開放ハンドラ をハンドラキュー上に設定すること。
重要
出力するデータに不正な値が設定されていた場合に正しく処理できない可能性があるため、事前にアプリケーション側で不正な値でないかをチェックすること。
重要
デフォルトの動作では1レコード毎にファイルへの書き込みを行う。 大量データを出力する場合はレコード毎にファイルに書き込むと性能要件を満たせない可能性がある。 そのような場合は、1レコード毎でなく指定したバッファサイズで書き込みを行うようにデフォルトの動作を変更して対応すること。
下記のコンポーネント定義を追加することで、1レコード毎でなく指定したバッファサイズで書き込みを行うようにできる。
<!-- コンポーネント名はdataFormatConfigとする -->
<component name="dataFormatConfig" class="nablarch.core.dataformat.DataFormatConfig">
<property name="flushEachRecordInWriting" value="false" />
</component>
出力に使用するバッファサイズは FileRecordWriterHolder の open メソッドで指定できる。
ファイルダウンロードで使用する¶
データレコードの内容をファイルダウンロード形式でクライアントに応答する方法について解説する。
ファイルダウンロード形式のレスポンスは、 DataRecordResponse を使用することで実現できる。
以下に実装例を示す。
- ポイント
- DataRecordResponse 生成時に、 フォーマット定義ファイルが格納された論理パス名と、フォーマット定義ファイル名を指定する。
- DataRecordResponse#write を使って、 データを出力する。(複数のレコードをダウンロードする場合には、繰り返し出力する)
- Content-Type 及び Content-Disposition を設定する。
- 業務アクションから DataRecordResponse を返却する。
public HttpResponse download(HttpRequest request, ExecutionContext context) {
// 業務処理
// ダウンロードデータを格納したMapの作成する。
Map<String, Object> user = new hashMap<>()
user.put("name", "なまえ");
user.put("age", 30);
// フォーマット定義ファイルが格納された論理パス名と
// フォーマット定義ファイル名を指定してDataRecordResponseを生成する。
DataRecordResponse response = new DataRecordResponse("format", "users_csv");
// ダウンロードデータを出力する。
response.write(user);
// Content-Typeヘッダ、Content-Dispositionヘッダを設定する
response.setContentType("text/csv; charset=Shift_JIS");
response.setContentDisposition("メッセージ一覧.csv");
return response;
}
補足
フォーマット定義ファイルの格納パスは、 ファイルパス管理 に設定する必要がある。
アップロードしたファイルを読み込む¶
アップロードしたファイルを読み込む方法について解説する。
この機能では、以下の2種類の方法でアップロードしたファイルを読み込むことが出来る。 アップロードヘルパーを使った読み込み に記載のある通り、 汎用データフォーマット(本機能)のみを使った読み込み の使用を推奨する。
- 汎用データフォーマット(本機能)のみを使ったアップロードファイルの読み込み
後述のアップロードヘルパーを使わずに本機能のAPIを使用したアップロードファイルのロード処理について解説する。
以下に実装例を示す。
- ポイント
- HttpRequest#getPart を呼び出してアップロードされたファイルを取得する。
- HttpRequest#getPart の引数には、パラメータ名を指定する。
- FilePathSetting からフォーマット定義ファイルの File オブジェクトを取得する。
- フォーマット定義ファイルを指定し、 FormatterFactory から DataRecordFormatter を生成する。
- DataRecordFormatter にアップロードファイルを読み込むための InputStream を設定する。 設定する InputStream の実装クラスは、 mark/reset がサポートされている必要がある。
- DataRecordFormatter のAPIを呼び出し、アップロードファイルのレコードを読み込む。
public HttpResponse upload(HttpRequest req, ExecutionContext ctx) { // アップロードしたファイルの情報を取得 final List<PartInfo> partInfoList = request.getPart("users"); // フォーマット定義ファイルのFileオブジェクトを取得する final File format = FilePathSetting.getInstance() .getFile("format", "users-layout"); // フォーマット定義ファイルを取得し、アップロードファイルを読み込むためのフォーマッタを生成する。 try (final DataRecordFormatter formatter = FormatterFactory.getInstance() .createFormatter(format)) { // アップロードファイルを読み込むためのInputStreamをフォーマッタに設定し初期化する。 // mark/resetがサポートされている必要が有るため、BufferedInputStreamでラップする。 formatter.setInputStream(new BufferedInputStream(partInfoList.get(0).getInputStream())) .initialize(); // レコードが終わるまで繰り返し処理を行う。 while (formatter.hasNext()) { // レコードを読み込む。 final DataRecord record = formatter.readRecord(); // レコードに対する処理を行う final Users users = BeanUtil.createAndCopy(Users.class, record); // 以下省略 } } catch (IOException e) { throw new RuntimeException(e); } }
- アップロードヘルパーを使用したアップロードファイルの読み込み
アップロードヘルパー( UploadHelper )を使用すると、 ファイルの読み込み、バリデーション、データベースへの保存を簡易的に実行出来る。
しかし、この機能では以下の制限(デメリット)があるため、 汎用データフォーマット(本機能)のみを使ったアップロードファイルの読み込み を使用することを推奨する。
- 入力値のチェックは Nablarch Validation に限定される。(推奨される Bean Validation が使用できない。)
- 拡張可能ではあるが、難易度が高く容易に要件を満たす実装ができない。
以下にシングルレイアウトのアップロードファイルに対して、入力チェックを行いデータベースに登録する例を示す。
- ポイント
- HttpRequest#getPart を呼び出してアップロードされたファイルを取得する。
- HttpRequest#getPart の引数には、パラメータ名を指定する。
- 取得したアップロードファイルを元に UploadHelper を生成する。
- UploadHelper#applyFormat を使って、フォーマット定義ファイルを設定する。
- setUpMessageIdOnError を使って、バリデーションエラー用のメッセージIDを設定する。
- validateWith を使って、バリデーションを実行するJava Beansクラスとバリデーションメソッドを設定する。
- importWith を使って、バリデーション実行後のJava Beansオブジェクトの内容をデータベースに登録する。
public HttpResponse upload(HttpRequest req, ExecutionContext ctx) { PartInfo partInfo = req.getPart("fileToSave").get(0); // 全件一括登録 UploadHelper helper = new UploadHelper(partInfo); int cnt = helper .applyFormat("N11AC002") // フォーマットを適用する .setUpMessageIdOnError("format.error", // 形式エラー時のメッセージIDを指定する "validation.error", // バリデーションエラー時のメッセージIDを指定する "file.empty.error") // ファイルが空の場合のメッセージIDを指定する .validateWith(UserInfoTempEntity.class, // バリデーションメソッドを指定する "validateRegister") .importWith(this, "INSERT_SQL"); // INSERT文のSQLIDを指定する }
補足
nablarch.fw.web.upload.util パッケージ内のクラスのドキュメントを合わせて参照すること。
JSONやXMLの階層構造のデータを読み書きする¶
JSONやXMLの階層構造データを読み書きする際のMapの構造について解説する。
JSONやXMLのような階層構造のデータを読み込んだ場合、Mapのキー値は各階層の要素名をドット( . )で囲んだ値となる。
以下に例を示す。
- フォーマット定義ファイル
JSONの場合には、 file-type を
JSONに読み替えること。 階層構造を表すフォーマット定義ファイルの定義方法は、 階層構造の定義 を参照。file-type: "XML" text-encoding: "UTF-8" [users] # ルート要素 1 user [0..*] OB [user] # ネストした要素 1 name [0..1] N # 最下層の要素 2 age [0..1] X9 3 address [0..1] N
重要
親要素が任意であり、親要素が存在する場合のみ子要素を必須、といった設定には対応していない。 そのため、階層構造のデータをフォーマット定義ファイルに定義する際は、全て任意項目として定義することを推奨する。
- Mapの構造
上記フォーマット定義ファイルを使って、XML及びJSONにデータを出力するMapの構造は以下のようになる。
- ポイント
- 階層構造の場合、「親要素名 + ”.” + 子要素名」形式でMapに値を設定する。
- 階層構造が深い場合は、更に
.で要素名が連結される。 - 最上位の要素名は、キーに含める必要はない
- 配列要素の場合添字(0から開始)を設定する。
Map<String, Object> data = new HashMap<String, Object>(); // user配列要素の1要素目 data.put("user[0].name", "なまえ1"); data.put("user[0].address", "住所1"); data.put("user[0].age", 30); // user配列要素の2要素目 data.put("user[1].name", "なまえ2"); data.put("user[1].address", "住所2"); data.put("user[1].age", 31);
- XMLおよびJSONの構造
上記フォーマット定義ファイルに対応したXML及びJSONの構造は以下のとおり。
- XML
<?xml version="1.0" encoding="UTF-8"?> <users> <user> <name>なまえ1</name> <address>住所1</address> <age>30</age> </user> <user> <name>なまえ2</name> <address>住所2</address> <age>31</age> </user> </users>
- JSON
{ "user": [ { "name": "なまえ1", "address": "住所1", "age": 30 }, { "name": "ななえ2", "address": "住所2", "age": 31 } ] }
XMLでDTDを使う¶
重要
本機能でXMLを入力する場合、DTDをデフォルトで使用できない。DTDを使用したXMLを読み込もうとした場合、例外が発生する。 これは XML外部実体参照(XXE) を防止するための措置である。
読み込み対象となるXMLが信頼できる場合は、 XmlDataParser の allowDTD プロパティを使用してDTDの使用を許可できる。
使用方法は下記の通り。
XmlDataParser という名前で明示的にコンポーネント設定ファイルに設定を記載し、DTDの使用を許可する。
<?xml version="1.0" encoding="UTF-8"?>
<component-configuration
xmlns="http://tis.co.jp/nablarch/component-configuration"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://tis.co.jp/nablarch/component-configuration component-configuration.xsd">
<component name="XmlDataParser" class="nablarch.core.dataformat.XmlDataParser">
<!--
DTDの使用を許可する。
XXE攻撃の危険性があるため、信頼できるXML以外には使用してはならない。
-->
<property name="allowDTD" value="true" />
</component>
</component-configuration>
XMLで名前空間を使う¶
接続先システムとの接続要件で、名前空間を使用しなければならない場合がある。 この場合は、フォーマット定義ファイルにて名前空間を定義することで対応できる。
以下に例を示す。
- ポイント
- 名前空間は、名前空間を使用する要素に「”?@xmlns:” + 名前空間」として定義する。
タイプは、
Xとし、フィールドコンバータ部にURIを指定する。 - 名前空間は、「名前空間 + ”:” + 要素名」形式で表す。
- 入出力対象データのMapのキー値は、「名前空間+要素名(先頭大文字)」となる。
- 名前空間は、名前空間を使用する要素に「”?@xmlns:” + 名前空間」として定義する。
タイプは、
- フォーマット定義ファイル
file-type: "XML" text-encoding: "UTF-8" [testns:data] # 名前空間の定義 1 ?@xmlns:testns X "http://testns.hoge.jp/apply" 2 testns:key1 X
- XMLデータ
上記フォーマット定義ファイルに対応したXMLは以下のとおり。
<?xml version="1.0" encoding="UTF-8"?> <testns:data xmlns:testns="http://testns.hoge.jp/apply"> <testns:key1>value1</testns:key1> </testns:data>
- Mapデータ
入出力対象のMapの構造は以下のとおり。
Map<String, Object> data = new HashMap<String, Object>(); data.put("testnsKey1", "value1");
XMLで属性を持つ要素にコンテンツを定義する¶
XMLで属性を持つ要素にコンテンツを定義したい場合は、 フォーマット定義ファイルにコンテンツを表すフィールドを定義する。
設定例を以下に示す。
- ポイント
- コンテンツを表すフィールド名には
bodyを指定する。 コンテンツを表すフィールド名をデフォルトから変更したい場合は、 XMLで属性を持つ要素のコンテンツ名を変更する を参照。
- コンテンツを表すフィールド名には
- フォーマット定義ファイル
file-type: "XML" text-encoding: "UTF-8" [parent] 1 child OB [child] 1 @attr X 2 body X
- XMLデータ
上記フォーマット定義ファイルに対応したXMLは以下のとおり。
<?xml version="1.0" encoding="UTF-8"?> <parent> <child attr="value1">value2</child> </parent>
- Mapデータ
入出力対象のMapの構造は以下のとおり。
Map<String, Object> data = new HashMap<String, Object>(); data.put("child.attr", "value1"); data.put("child.body", "value2");
文字の置き換え(寄せ字)を行う¶
寄せ字機能を使うことで、外部からデータを読み込む際に、システムで使用可能な文字に置き換えることが出来る。
以下に使用方法を示す。
- 置き換えルールを定義したプロパティを作成する
propertiesファイルには、「置き換え前の文字=置き換え後の文字」形式で、置き換えルールを定義する。
置き換え前、置き換え後の文字に定義できる値は、ともに1文字のみである。 また、サロゲートペアには対応していない。
コメントなどの記述ルールは、 java.util.Properties を参照。
髙=高 﨑=崎 唖=■
補足
接続先ごとに置き換えルールを定義する場合には、複数のpropertiesファイルを作成する。
- 置き換えルールの設定をコンポーネント設定ファイルに追加する
- ポイント
- CharacterReplacementManager をコンポーネント名
characterReplacementManagerで設定する。 - configList プロパティにリスト形式で CharacterReplacementConfig を設定する。
- 複数のpropertiesファイルを定義する場合は、 typeName プロパティに異なる名前を設定する。
- CharacterReplacementManager をコンポーネント名
<component name="characterReplacementManager" class="nablarch.core.dataformat.CharacterReplacementManager"> <property name="configList"> <list> <!-- Aシステムとの寄せ字ルール --> <component class="nablarch.core.dataformat.CharacterReplacementConfig"> <property name="typeName" value="a_system"/> <property name="filePath" value="classpath:a-system.properties"/> <property name="encoding" value="UTF-8"/> </component> <!-- Bシステムとの寄せ字ルール --> <component class="nablarch.core.dataformat.CharacterReplacementConfig"> <property name="typeName" value="b_system"/> <property name="filePath" value="classpath:b-system.properties"/> <property name="encoding" value="UTF-8"/> </component> </list> </property> </component>
- 初期化コンポーネントの設定
上記で設定した CharacterReplacementManager を初期化対象のリストに設定する。
<component name="initializer" class="nablarch.core.repository.initialization.BasicApplicationInitializer"> <property name="initializeList"> <list> <!-- 省略 --> <component-ref name="characterReplacementManager" /> </list> </property> </component>
- フォーマット定義ファイルにどの置き換えルールを使用するかを定義する
入出力時に文字の置き換えを行う場合は、 replacement を使用する。
replacement の引数には、上記で設定した置き換えルールの typeName を設定する。
# Aシステムとの置き換えルールを適用 1 name N(100) replacement("a_system") # Bシステムとの置き換えルールを適用 1 name N(100) replacement("b_system")
拡張例¶
フィールドタイプを追加する¶
Nablarchが提供する標準データタイプ では要件を満たせない場合がある。 例えば、文字列タイプのパディング文字がバイナリの場合などが該当する。
このような場合は、プロジェクト固有のフィールドタイプを定義することで対応する。
以下に手順を示す。
- フィールドタイプを処理するための DataType 実装クラスを作成する。
- 追加したフィールドタイプを有効にするため、フォーマットに応じたファクトリの継承クラスを作成する。
- 作成したファクトリクラスを、フォーマットに応じた設定クラスのプロパティに設定する。
詳細な手順は以下のとおり。
- フィールドタイプに対応したデータタイプ実装の追加
DataType を実装したクラスを作成する。
補足
標準のフィールドタイプ実装は、 nablarch.core.dataformat.convertor.datatype パッケージ配下に配置されている。 実装を追加する際には、これらのクラスを参考にすると良い。
- フォーマットに応じたファクトリの継承クラスの作成
追加したフィールドタイプを有効にするためには、 フォーマットに応じたファクトリの継承クラスを作成する。
以下にフォーマット毎のファクトリクラスを示す。
フォーマット ファクトリクラス名 Fixed(固定長) FixedLengthConvertorFactory Variable(可変長) VariableLengthConvertorFactory JSON JsonDataConvertorFactory XML XmlDataConvertorFactory Fixed(固定長)の場合の実装例を以下に示す。
public class CustomFixedLengthConvertorFactory extends FixedLengthConvertorFactory { @Override protected Map<String, Class<?>> getDefaultConvertorTable() { final Map<String, Class<?>> defaultConvertorTable = new CaseInsensitiveMap<Class<?>>( new ConcurrentHashMap<String, Class<?>>(super.getDefaultConvertorTable())); defaultConvertorTable.put("custom", CustomType.class); return Collections.unmodifiableMap(defaultConvertorTable); } }
- フォーマットに応じた設定クラスのプロパティに設定
フォーマットに応じた設定クラスのプロパティに、先ほど作成したファクトリクラスを設定する。
以下にフォーマット毎の設定クラスとプロパティを示す。
フォーマット 設定クラス名(コンポーネント名) プロパティ名 Fixed(固定長) FixedLengthConvertorSetting (fixedLengthConvertorSetting) fixedLengthConvertorFactory Variable(可変長) VariableLengthConvertorSetting (variableLengthConvertorSetting) variableLengthConvertorFactory JSON JsonDataConvertorSetting (jsonDataConvertorSetting) jsonDataConvertorFactory XML XmlDataConvertorSetting (xmlDataConvertorSetting) xmlDataConvertorFactory Fixed(固定長)の場合の設定例を以下に示す。
<component name="fixedLengthConvertorSetting" class="nablarch.core.dataformat.convertor.FixedLengthConvertorSetting"> <property name="fixedLengthConvertorFactory"> <component class="com.sample.CustomFixedLengthConvertorFactory" /> </property> </component>
重要
フォーマットに応じた設定クラスの convertorTable プロパティを使用してフィールドタイプを追加できるが、 以下の理由により使用は推奨しない。
- 追加したいフィールドタイプだけでなく、元々デフォルトで定義されていたフィールドタイプも全て設定する必要がある。 そのため、もしバージョンアップによりデフォルトのフィールドタイプが変更となった場合、 自動的に変更が適用されず手動で設定を修正しなければならないため手間が掛かる。
- デフォルト定義はファクトリクラスに実装されており、ソースコードをもとにコンポーネント設定ファイルに定義を追加していく必要があるため、 設定ミスを起こしやすい。
XMLで属性を持つ要素のコンテンツ名を変更する¶
属性を持つ要素のコンテンツ名を変更するには、
以下のクラスをコンポーネント設定ファイルに設定し、contentName プロパティに変更後のコンテンツ名をそれぞれ設定する。
コンポーネント設定ファイルの設定例を以下に示す。
- ポイント
- XmlDataParser のコンポーネント名は
XmlDataParserとすること - XmlDataBuilder のコンポーネント名は
XmlDataBuilderとすること
- XmlDataParser のコンポーネント名は
<component name="XmlDataParser" class="nablarch.core.dataformat.XmlDataParser">
<property name="contentName" value="change" />
</component>
<component name="XmlDataBuilder" class="nablarch.core.dataformat.XmlDataBuilder">
<property name="contentName" value="change" />
</component>