3.2.1. 自動テストフレームワーク¶
3.2.1.1. 特徴¶
3.2.1.1.1. JUnit4ベース¶
自動テストフレームワークは、JUnit4をベースとしている。 各種アノテーション、assertメソッドやMatcherクラスなど、JUnit4で提供されている機能を使用する。
3.2.1.1.2. テストデータの外部化¶
テストデータをExcelファイルに記述できる。 データベース準備データや期待するテスト結果などを記載したExcelファイルを 自動テストフレームワークのAPIを通じて使用できる。
3.2.1.1.3. Nablarchに特化したテスト補助機能を提供¶
トランザクション制御やシステム日付設定など、Nablarchアプリケーションに特化したAPIを用意する。
3.2.1.2. 自動テストフレームワークの構成¶
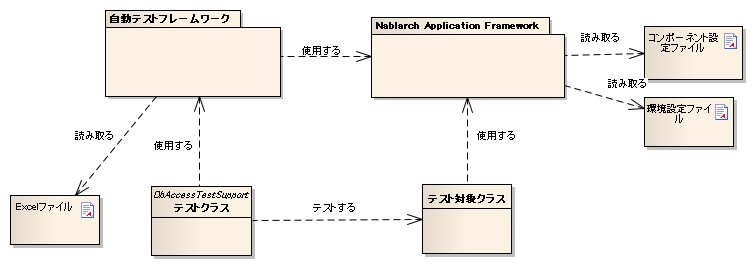
| 構成物 | 説明 | 作成者 |
|---|---|---|
| テストクラス | テスト処理を記述する。 | アプリケーションプログラマ |
| テスト対象クラス | テスト対象となるクラス。 | アプリケーションプログラマ |
| Excelファイル | テストデータを記載する。自動テストフレ ームワークを使用することにより、データ を読み取ることができる。 | アプリケーションプログラマ |
| コンポーネント設定ファイル・ 環境設定ファイル | テスト実行時の各種設定を記載する。 | アプリケーションプログラマ(個別のテス トに固有の設定が必要な場合) |
| 自動テストフレームワーク | テストに必要な機能を提供する。 | - |
| Nablarch Application Framework | フレームワーク本体(本機能の対象外) | - |
3.2.1.3. テストメソッド記述方法¶
JUnit4のアノテーションを使用する。 テストメソッドに @Test アノテーションを付与する。
public class SampleTest { @Test public void testSomething() { // テスト処理 } }
補足
@Beforeや@Afterなどのアノテーションも使用できる。これらのアノテーションを用いて、 テストメソッド前後にリソースの取得解放などの共通処理を行いたい場合は、 次の項を参照( テスト実行前後に共通処理を行いたい。 )。
3.2.1.4. Excelによるテストデータ記述¶
データベースの準備データやデータベース検索結果などのデータを表すには、 Javaソースコードよりスプレッドシートのほうが可読性や編集のしやすさという点で有利である。 Excelファイルを使用することにより、このようなデータをスプレッドシート形式で扱うことができる。
3.2.1.4.1. 命名規約¶
Excelファイル名、ファイルパスには推奨される規約が存在する。この規約に従うことにより、テストクラスで明示的にディレクトリ名やファイル名を指定してファイルを読み込む必要がなくなり、簡潔にテストソースコードを記述できる。また明示的にパスを指定することで任意の場所のExcelファイルを読み込むことも可能である。
3.2.1.4.1.1. パス、ファイル名に関する規約¶
ファイル名、パスに関して推奨される規約は以下の通り。
- Excelファイル名は、テストソースコードと同じ名前にする(拡張子のみ異なる)。
- Excelファイルを、テストソースコードと同じディレクトリに配置する。
例を以下に示す。
| ファイルの種類 | 配置ディレクトリ | ファイル名 |
|---|---|---|
| テストソースファイル | <PROJECT_ROOT>/test /jp/co/tis/example/db/ | ExampleDbAcessTest.java |
| Excelファイル | ExampleDbAcessTest.xlsx [1] |
| [1] | Excel ファイルは、 Excel2003以前のファイル形式(拡張子 xls の形式)および Excel2007 以降のファイル形式(拡張子 xlsx の形式)に対応している。 |
3.2.1.4.1.2. Excelシート名に関する規約¶
Excelシートについては、以下の規約が推奨される。
- 1テストメソッドにつき1シート用意する。
- シート名はテストメソッド名と同名にする。
例を以下に示す。
| テストメソッド | @Test public void testInsert() |
| Excelシート名 | testInsert |
補足
シートに関する規約は、「制約」事項ではない。 テストメソッド名とExcelシート名が同名でなくても正しく動作する。 今後の機能追加は上記規約をデフォルトとして開発されるので、命名規約に準拠することを推奨する。 仮に命名規約を変更する場合であってもプロジェクト内で統一を図ること。
3.2.1.4.2. シート内の構造¶
Excelシートの記述方法関する規約について説明を行う。 以下にシートの記述例を記載する。
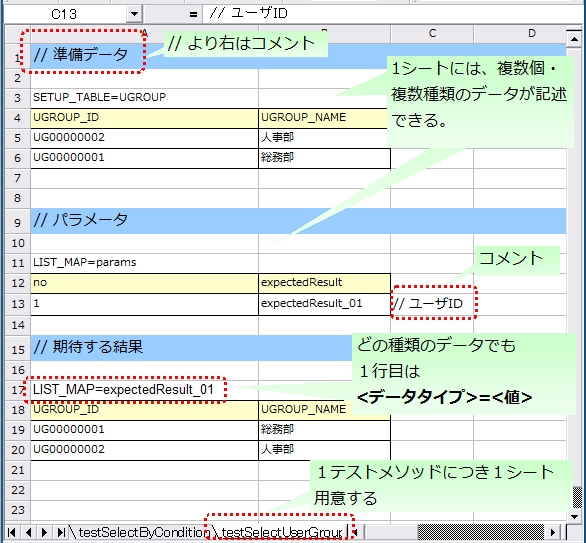
シート内には、データベースに格納するデータやデータベース検索結果など、さまざまな種類のデータを記載できる。テストデータの種類を判別するために「データタイプ」というメタ情報をテストデータに付与する必要がある。「データタイプ」は、そのテストデータが何を表しているかを示す。
現状、以下のデータタイプが用意されている。
| データタイプ名 | 説明 | 設定する値 |
|---|---|---|
| SETUP_TABLE | テスト実行前にデータベースに登録するデータ | 登録対象のテーブル名 |
| EXPECTED_TABLE | テスト実行後の期待するデータベースのデータ 省略したカラムは、比較対象外となる。 | 確認対象のテーブル名 |
| EXPECTED_COMPLETE_TABLE | テスト実行後の期待するデータベースのデータ 省略したカラムにはデフォルト値が設定されているものとして扱われる。 | 確認対象のテーブル名 |
| LIST_MAP | List<Map<String,String>>形式のデータ | シート内で一意になるID 期待値のID(任意の文字列) |
| SETUP_FIXED | 事前準備用の固定長ファイル | 準備ファイルの配置場所 |
| EXPECTED_FIXED | 期待値を示す固定長ファイル | 比較対象ファイルの配置場所 |
| SETUP_VARIABLE | 事前準備用の可変長ファイル | 準備ファイルの配置場所 |
| EXPECTED_VARIABLE | 期待値を示す可変長ファイル | 比較対象ファイルの配置場所 |
| MESSAGE | メッセージング処理のテストで使用するデータ | 固定値 [2] |
| EXPECTED_REQUEST_HEADER_MESSAGES | 要求電文(ヘッダ)の期待値を示す固定長ファイル | リクエストID |
| EXPECTED_REQUEST_BODY_MESSAGES | 要求電文(本文)の期待値を示す固定長ファイル | リクエストID |
| RESPONSE_HEADER_MESSAGES | 応答電文(ヘッダ)を示す固定長ファイル | リクエストID |
| RESPONSE_BODY_MESSAGES | 応答電文(本文)を示す固定長ファイル | リクエストID |
| [2] | setUpMessagesまたはexpectedMessages |
また、データの個数も複数記述できる。
データの種類に依らない共通の書式は以下の通り。
- データ1行目は「データタイプ=値」の形式で、データタイプと値を記載する。
- 2行目以降の書式はデータタイプにより異なる。
データタイプとは、そのデータが何を表すかを特定するための情報である。 例えばそのデータが、データベースに投入されるべきデータである場合は、データタイプ”SETUP_TABLE”を使用する。
例えば、以下のようにデータタイプを記載した場合、そのデータがCOMPOSERテーブルに準備データとして登録されるべきものであることを示している。
SETUP_TABLE=COMPOSER
| NO | FIRST_NAME | LAST_NAME |
|---|---|---|
| 00001 | Steve | Reich |
| 00002 | Phillip | Glass |
3.2.1.4.3. コメント¶
セル内に”//”から開始する文字列を記載した場合、そのセルから右のセルは全て読み込み対象外となる。テストデータ自体には含めたくないが、可読性を向上させるために付加情報を記載したい場合には、コメント機能が使用できる。
以下の例では、2行目でテーブルの論理名を、4行目末尾で期待する結果についてコメントしている。
EXPECTED_TABLE=PLAYER
| NO | FIRST_NAME | LAST_NAME | ADDRESS | |
|---|---|---|---|---|
| //番号 | 名 | 姓 | 住所 | |
| 0001 | Andres | Segovia | Spain | |
| 0002 | Julian | Bream | England | // このレコードが追加される |
3.2.1.4.4. マーカーカラム¶
テストデータを記述する際、実際のデータには含めたくないがExcelシート上には記述しておきたい場合がある。前述の「コメント」を使用することにより、実際のデータには含まれない情報を記述できるが、「コメント」には、そのセルから右のセルを読み込み対象外にするという性質があるため、左端(または中央)のセルにはコメントを使用できない。
このような場合は、「マーカーカラム」を使用することで、実際のデータには含まれないが Excelシートの見た目上は存在するデータを記述できる。
テストデータの見出し行において、カラム名が半角角括弧で囲まれている場合、そのカラムは「マーカーカラム」とみなされる。マーカーカラムに該当する列はテスト実行時には読み込まれない。
例えば、以下のようなテストデータがあるとする。
LIST_MAP=EXAMPLE_MARKER_COLUMN
| [no] | id | name |
|---|---|---|
| 1 | U0001 | 山田 |
| 2 | U0002 | 田中 |
上記のテストデータは、半角角括弧で囲まれているカラム[no]が無視されるため、 テスト実行時には以下のテストデータと等価となる。
LIST_MAP=EXAMPLE_MARKER_COLUMN
id name U0001 山田 U0002 田中
ここではLIST_MAPの例を挙げたが、それ以外のデータタイプでも同様に使用できる。
3.2.1.4.5. セルの書式¶
セルの書式には、文字列のみを使用する。 テストデータを作成する前に、全てのセルの書式を文字列に設定しておくこと。
罫線やセルの色付けについては任意に設定可能である。罫線やセルの色付けを行うことでデータが見やすくなり、レビュー品質や保守性の向上が期待できる。
重要
3.2.1.4.6. セルへの特殊な記述方法¶
自動テストの利便性を向上させるために、いくつかの特殊記法を提供する。 下記表が、本フレームワークで提供する特殊な記述方法となっている。
| 記述方法 (セルに記述する値) | 自動テスト内での値 [3] | 説明 |
|---|---|---|
| null | null | セル内に、「null」 (半角で大文字、小文字の区別はしない) と記述されている場合は、「null」値として扱う。例えば、データベースにnull値を登録したい場合や、期待値でnull値を設定したい場合に使用する。 |
| Null | ||
| “null” | 文字列のnull | 文字列の前後がダブルクォート(半角、全角問わず)で囲われている場合は、前後のダブルクォートを取り除いた文字列を扱う。[4] 例えば、「null」や「NULL」を文字列として扱う必要がある場合には、記述方法にあるように 「”null”」や「”NULL”」と記述を行う。 また、セルの値にスペースがあることを解りやすくする目的で、記述方法にあるよ うに「”1?”」や、「”?”」とすることもできる。 |
| “NULL” | ||
| “1⊔” | 1⊔ | |
| “⊔” | ⊔ | |
| “1△” | 1△ | |
| “△△” | △△ | |
| “”“ | “ | |
| “” [5] | 空文字列 | |
| ${systemTime} | システム日時 [6] | システム日時を記載したい場合に使用する |
| ${updateTime} | ${systemTime}の別名。特にデータベースのタイムスタンプ更新時の期待値として使用する。 | |
| ${setUpTime} | コンポーネント設定ファイルに 記載された固定値 | データベースセットアップ時のタイムスタンプに、決まった値を使用したい場合に使用する。 |
| ${文字種,文字数} [7] | 指定した文字種を指定した文字 数分まで増幅した値 | 使用可能な文字列は下記の通り。 半角英字,半角数字,半角記号,半角カナ,全角英字,全角数字, 全角ひらがな,全角カタカナ,全角漢字,全角記号その他,外字 |
| ${binaryFile:ファイルパ ス} | BLOB列に格納するバイナリデー タ | BLOB列にファイルのデータを格納したい場合に使用する。 ファイルパスはExcelファイルからの相対パスで記述する。 |
| \r | CR | 改行コードを明示的に記述する場合に使用する。 [8] |
| \n | LF |
補足
凡例
- ⊔ は、半角スペースの意
- △は、全角スペースの意
- CR は、改行コードCR(0x0D)の意
- LF は、改行コードLF(0x0A)の意
| [3] | セルから読み込み後に自動テストフレームワークにて変換される。 |
| [4] |
|
| [5] | この記法を使用することで、空行を表すことができる。 『テストデータに空行を記述したい』の項を参照。 |
| [6] | コンポーネント設定ファイルにて設定されたSystemTimeProvider実装クラスから取得したTimestampの文字列形式に変換される。具体的には、2011-04-11 01:23:45.0 というような値に変換される。 |
| [7] | 本記法は単独でも使用可能であるし、組み合わせて使用することもできる。 以下に例を示す。
|
| [8] | Excelセル内の改行(Alt+Enter)はLFとして扱われる。これは本機能とは関係のないExcelの仕様である。 改行コードLFを表したい場合は、単にセル内で改行(Alt+Enter)すればよい。 以下に例を示す。
|
3.2.1.5. 注意事項¶
3.2.1.5.1. テストメソッドの実行順序に依存しないテストを作成する¶
テストソースコード、テストデータ作成時には、テストメソッドの実行順序によって、テスト結果が変わらないように留意する。単に順序だけでなく、クラス単体でテストしても、複数まとめてテストしても同じ結果にならなければならない。
特に、本フレームワークではテスト中にコミットが行われるため、前後のテストによってデータベースの内容が変更される可能性が高い。よって、自テストクラスで必要となる事前条件については、全て自テストクラス内で準備するようにしておかなければならない。
これにより、以下のような効果が得られる。
- テストの実行順序によって偶然テストが失敗したり偶然成功する、という事態を防ぐ。
- そのテストのデータまたはソースコードだけで、事前条件が分かる。
マスタデータのような基本的に読み取り専用のテーブルの準備については、共通のExcelファイルを用意してそこに記載すること。テスト実行前に1回だけ実行するか、テスト実行前に事前に準備済みという前提でテストを実行するようにする。
この手法には、以下のようなメリットがある。
- マスタ系のデータを、プロジェクト全体で再利用できる。
- テストデータのメンテナンスが容易になる。
- テスト実行速度が上がる。
補足
マスタデータの投入には、マスタデータ投入ツールを使用する。また、マスタデータ復旧機能により、テスト内で発生したマスタデータの変更をテスト終了時に自動的に元の状態に戻すことができる。これにより、マスタデータに変更が必要なテストケースであっても、他のテストケースに影響無く実行できる。
3.2.1.5.2. テストデータは全てExcelシートに記述する¶
Excelとテストソースコードとでテストデータが混在していると、可読性、保守性が低下してしまう。テストソースコード中にはテストデータを記載せず、テストデータは全てExcelシートに記載すること。
- Excelシートを見れば、テストケースのバリエーションを把握することができる。
- テストデータはExcelシート、テストロジックはテストソースコードと役割分担が明確になる。
- Excelシートを読み込む構造にしておくことで、容易にテストケースを追加できる。
- テストソースコードの重複を大幅に削減できる(テストソースコード中に単純にリテラル値でデータを記載すると、データのバリエーションが増加すると重複したコードが作られてしまう)。
3.2.1.5.3. 複数のデータタイプ使用時はデータタイプごとにまとめてデータを記述する¶
複数のデータタイプを使用する場合、使用するデータタイプごとにまとめてデータを記述すること。 複数のデータタイプを混在させてデータを記述してしまうと、データの読み込みが途中で終了しテストが正しく実行されない。
例えば、 以下のようにデータタイプを記述した場合、 TABLE2 までのデータしか評価されず、
TABLE3 以降のデータに誤りがあってもテストは成功してしまう。
EXPECTED_TABLE=TABLE1
:
EXPECTED_COMPLETE_TABLE=TABLE2
:
EXPECTED_TABLE=TABLE3
:
EXPECTED_COMPLETE_TABLE=TABLE4
:
全てのデータが正しく評価されるようにするには、 以下のようにデータタイプごとにまとめてデータを記述すること。
EXPECTED_TABLE=TABLE1
:
EXPECTED_TABLE=TABLE3
:
EXPECTED_COMPLETE_TABLE=TABLE2
:
EXPECTED_COMPLETE_TABLE=TABLE4
: