4. ETL¶
JSR352に準拠したバッチアプリケーション 上で動作するETL機能を提供する。
ETLとは以下の略である。
- Extract(外部データの抽出)
- Transform(抽出したデータの検証と変換)
- Load(変換したデータの出力)
ETLを使うことで以下のメリットが得られる。
- インタフェースファイルの取り込みや作成処理を、設定ファイルとSQLおよびBeanの作成のみで実現できる。
- JSR352に準拠したバッチアプリケーション のBatchletやChunkステップとして各フェーズが提供されているため、ステップを追加することで容易に任意の処理を追加できる。
補足
NablarchのETLは、厳密には一般的なETLとは各フェーズで行っている処理の内容が異なっている。 詳細は、後述の ETLの各フェーズの仕様 を参照。
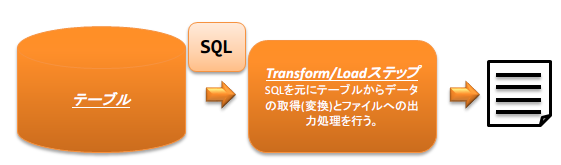
- ETLの処理イメージ
- ファイルの内容をデータベースへ登録

- データベースの内容をファイルへ出力
補足
ETLを使用したバッチアプリケーションの実例は、Exampleアプリケーション の以下のJOBを参照。
- etl-zip-code-csv-to-db-insert-batchlet
- etl-zip-code-csv-to-db-chunk
- etl-zip-code-db-to-csv-chunk
- etl-zip-code-db-to-fixedlength-chunk
- etl-zip-code-fixedlength-to-db-chunk
4.1. モジュール一覧¶
<dependency>
<groupId>com.nablarch.framework</groupId>
<artifactId>nablarch-etl</artifactId>
</dependency>
4.2. ETLの各フェーズの仕様¶
4.2.1. Extractフェーズ¶
Extractフェーズでは、ファイルの内容をデータベース上のワークテーブルに取り込む処理を行う。
- データのロード方法の選択
本機能では、以下の2種類のロード方法を提供している。
ロード方法 内容 Chunk Chunkステップを使用してデータをワークテーブルにロードする。
詳細は、 Extractフェーズ(Chunk)を使用する を参照。
SQL*Loader Oracle SQL*Loaderを使用してデータをワークテーブルにロードする。
使用方法は、 Extractフェーズ(SQL*Loader版)を使用する を参照。
4.2.2. Transformフェーズ¶
Transformフェーズでは、 Extractフェーズ でワークテーブルに取り込んだデータに対するバリデーションを行う。 なお、本機能では一般的なETLとは異なりデータの編集処理は Loadフェーズ にて行う。
詳細は、 Transformフェーズでバリデーションを行う を参照。
4.2.3. Loadフェーズ¶
Loadフェーズでは、データ変換用SQL文を実行し、データをデータベースやファイルに出力する。
- データのLoad方法の選択
本機能では出力先などに応じて以下のLoad方法を提供している。
ロード方法 内容 ファイル出力 ファイルに出力する場合に使用する。
詳細は Loadフェーズでファイルにデータを出力する を参照。
データベースの洗い替え ロード先テーブルのデータを削除後にワークテーブルのデータを登録する場合に使用する。
詳細は Loadフェーズでデータベースのデータの洗い替えを行う を参照。
データベースのマージ ロード先テーブルにワークテーブルのデータをマージする場合に使用する。
キーが一致するデータが存在する場合は更新処理が行われ、存在しない場合は登録処理が行われる。
マージモードに対応しているデータベースは、 MergeSqlGeneratorFactory を参照。
詳細は Loadフェーズでデータベースのデータのマージを行う を参照。
データベースへの登録 Chunkステップを使用してデータベースのテーブルにデータを登録する場合に使用する。
SQLだけでは編集処理を行えない場合にChunkステップのprocessorを追加することで、Java側で編集処理を行えるメリットがある。
詳細は Loadフェーズでデータベースへの登録を行う を参照
4.3. ETLを使用するバッチの設計ポイント¶
4.3.1. ファイル取り込み処理¶
ファイルを本テーブルに取り込む際の処理の流れは下の図のようになる。
ワークテーブルやエラーテーブルなどの設計が誤っていると実装が出来ないため、本章の内容を理解し設計を行うこと。
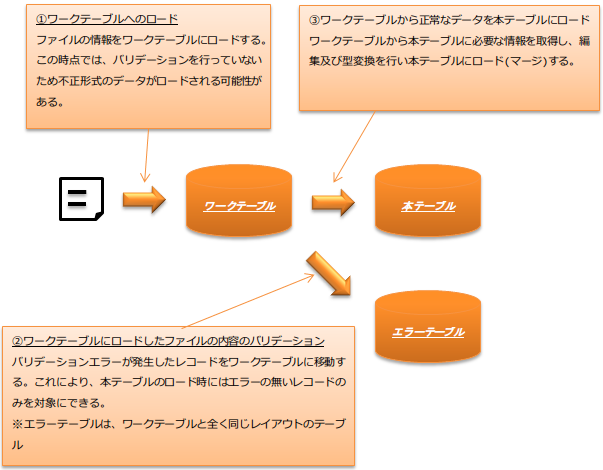
- ワークテーブル
取り込み対象のファイルの内容を保持するテーブル。
ワークテーブルは、 Extractフェーズ で取り込み対象ファイルの内容がロードされ、 Transformフェーズ 及び Loadフェーズ の入力テーブルとなる。
- ファイル内の各項目に対応したカラムについて
上記図の通りファイル内の項目に対応したカラムは、不正な値 [1] であってもワークテーブルにロードできるよう以下の指針に従い設計すること。
カラムの型 原則可変長の文字列型を使用する。
ただし、ファイル内のバイナリデータを保存するカラムに関しては、文字列型に変換出来ないためバイナリ型を使用する。
カラムのデータ長 CSVなどの可変長ファイルは、ファイル内の各項目の桁数が不明である。このため、想定外の桁数でもワークテーブルにロードできるよう、データベースで定義可能な最も大きい値とする。
固定長の場合は決められた長さで各項目を区切るため、項目長をカラムのデータ長として使用する。
- 行番号を格納するカラムについて
ファイルの行番号を保持するカラムを必ず定義する。カラム名は、
LINE_NUMBERとし整数型として定義する。 行番号カラムは後続のフェーズで以下のように使用するため必ず必要となる。フェーズ 利用目的 Transform バリデーション 時に、バリデーションエラーが発生した行番号をログに出力する際に使用する。 また、ワークテーブルからエラーが発生したレコードを削除する際の条件として使用する。 Load 洗い替え 及び マージ 処理でコミット間隔の制御を行う際に使用する。 補足
行番号カラムは本テーブルにはロードする必要がない。
データベースへの登録 を使用する場合、本テーブルに対応したEntityからSQLが自動生成されるため、行番号カラムは自動的に除外される。 洗い替え 及び マージ を使用する場合は、ワークテーブルから取得するSQLのSELECT句には行番号カラムを含めないようにすること。
上記以外の方法を使用して本テーブルにデータをロードする場合は、行番号を除外するよう設計及び実装を行うこと。
- エラーテーブル
バリデーション 時にエラーとなったレコードの退避先テーブル。
エラーテーブルは、ワークテーブルと全く同じレイアウトとすること。
- 本テーブル
本テーブルはアプリケーションの要件に従い設計する。ワークテーブルから本テーブルへデータをロードする際の変換処理は、 Loadフェーズ にて実施する。 行番号カラム で説明したように、行番号を保持するカラムは不要である。
補足
ワークテーブルの設計ポイント で説明したようにワークテーブルの各カラムの型は基本的に文字列型として定義する。 このため、本テーブルに取り込む際には型変換が必要となる。
データベースへの登録 を使用する場合は、本テーブルに対応したEntityの属性の型定義に従い自動的に型変換が行われる。 洗い替え 及び マージ を使用する場合は、 ワークテーブルからのデータ取得時のSQLで明示的な型変換を行う必要がある。 明示的な型変換を行わなかった場合、データベースにより暗黙的な型変換が行われるため注意すること。
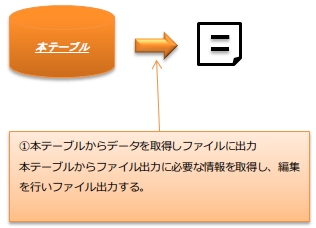
4.3.2. ファイル出力処理¶
本テーブルの内容をファイルに出力する際の処理の流れは下の図のようになる。 ファイル取り込み処理 とは異なり、ファイル出力処理には設計時の注意点などはない。 要件に従い、本テーブル及びファイルレイアウトの設計を行い、 ファイル出力 時にSQLを使用して値の編集などを行う。
4.4. 使用方法¶
4.4.1. ETL JOBを実行するための設定を行う¶
ETL JOBを実行するためには以下の設定ファイルが必要となる。
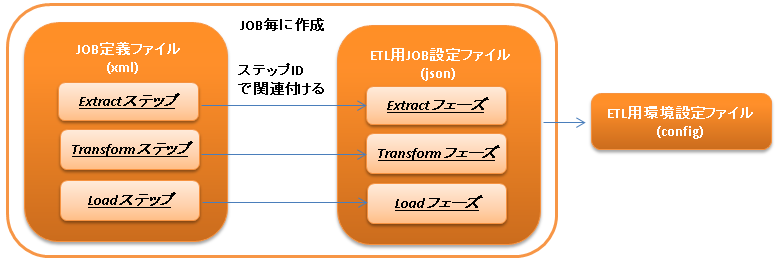
- ETL用環境設定ファイル
読み込むファイルパスなどの環境依存値の設定を行うファイル。
詳細は、 ETL用環境設定ファイルを作成する を参照。
- JOB定義ファイル
ETL JOBのJOB構成を定義するファイル。
詳細は、 JOB定義ファイルとETL用JOB設定ファイルを作成する および JSR352に準拠したバッチアプリケーション 及び JSR352 Specification を参照。
- ETL用JOB設定ファイル
JOB毎に必要となる各フェーズ(Extract/Transform/Load)の設定を行うファイル。
詳細は、 JOB定義ファイルとETL用JOB設定ファイルを作成する を参照。
4.4.2. ETL用環境設定ファイルを作成する¶
環境依存値はシステムリポジトリ機能の環境設定ファイルに設定する。 設定方法は、 依存値を設定する を参照。
ETLでは以下の環境依存値を設定する。
- ファイル入力を行う場合
nablarch.etl.inputFileBasePath 入力ファイルを配置するディレクトリのパス - ファイル出力を行う場合
nablarch.etl.outputFileBasePath 出力ファイルを配置するディレクトリのパス - Oracle SQL*Loaderを使用したデータのロード を行う場合
nablarch.etl.sqlLoaderControlFileBasePath ctlファイルを配置するディレクトリのパス nablarch.etl.sqlLoaderOutputFileBasePath 実行ログを出力するディレクトリのパス
4.4.3. JOB定義ファイルとETL用JOB設定ファイルを作成する¶
ETL用JOB設定ファイルを作成する際は、ファイル名を <<JOB ID>>.json とし、META-INF/etl-config/ 配下に配置する。
補足
ETL用JOB設定ファイルを配置するディレクトリのパスを変更したい場合は、 ETL用JOB設定ファイルを配置するディレクトリのパスを変更する を参照。
ジョブ設定ファイルは、以下からテンプレートをダウンロードし、ファイル内のコメントを参照し編集すること。
- Oracle SQL*Loaderを使用したファイル取り込みテンプレート
- JSR352のChunkを使用したファイル取り込みのテンプレート
- ファイル出力のテンプレート
補足
テンプレートで要件を満たせない場合には、テンプレートをベースにステップの追加や変更などを行うことで対応すること。 例えば、Chunkステップを用いてファイルをワークテーブルにロードし、マージモードを使用して本テーブルにデータをロードしたい場合には、 SQL*LoaderとChunkのテンプレートから必要なものを組み合わせてジョブを構成すると良い。
4.4.4. テーブルクリーニングステップを利用してテーブルのデータを削除する¶
ETLの処理の中で、テーブルのクリーニング(全削除)が必要となるシーンがある。 例えば、ワークテーブルへのデータロード(Extract)の前にワークテーブルを空にしておきたい場合が該当する。
このような場合は、テーブルクリーニング用のステップを定義することで対応する。
補足
JOB定義及びETL用JOB設定ファイルは、 JOB定義ファイルとETL用JOB設定ファイルを作成する の Oracle SQL*Loaderを使用したファイル取り込みテンプレート をダウンロードし編集すると良い。
- JOB定義
- batchletとしてステップを定義する。
- batchletクラスには、 tableCleaningBatchlet を設定する。
<!-- id及びnextは適宜変更すること --> <step id="truncate" next="extract"> <listeners> <!-- リスナーの設定は省略 --> </listeners> <batchlet ref="tableCleaningBatchlet" /> </step>
補足
TableCleaningBatchlet は、 データベースアクセス(JDBCラッパー) 機能を使用してデータのクリーニングを行う。 このため、 データベースアクセス(JDBCラッパー) を使用するための設定を事前に行う必要がある。
- ETL用JOB設定ファイル
JOB定義のステップ名(step id)に対応したキーに対して、以下の設定値を持つオブジェクトを設定する。
キー 設定する値 type truncateを固定で設定する。entities 削除対象のテーブルに対応したEntityクラスの完全修飾名を配列で設定する。
Entityクラスは、 ユニバーサルDAO のルールに従い作成すること。
- 設定例
"truncate": { "type": "truncate", "entities": [ "sample.SampleEntity1", "sample.SampleEntity2" ] }
4.4.5. Extractフェーズ(Chunk)を使用する¶
Chunkを使用したExtractフェーズの実装と設定について解説する。
補足
ワークテーブルの内容を事前に削除する必要がある場合は、Chunkステップの前処理として テーブルのクリーニング を行うようステップを定義すること。
補足
JOB定義及びETL用JOB設定ファイルは、 JOB定義ファイルとETL用JOB設定ファイルを作成する の JSR352のChunkを使用したファイル取り込みのテンプレート をダウンロードし編集すると良い。
- 入力ファイルとワークテーブルに対応したJava Beansの作成
入力ファイルとワークテーブルに対応したJava Beansを以下のルールに従い作成する。
行番号を保持する属性 ワークテーブルの設計について で説明したように、ワークテーブルには行番号を必ず保持させる。 このため、ワークテーブルに対応したJava Beansにも行番号を保持するための属性を定義する。
なお、行番号をもつ属性の追加は、 WorkItem を継承して実現すること。 WorkItem を継承していない場合、後続のフェーズが実行できなくなるため注意すること。
入力ファイルのレイアウトを定義 ファイルを読み込む FileItemReader は、 データバインド を使用する。 このため、 データバインド を参照しアノテーションを設定すること。 ワークテーブルのテーブルに関する定義 データベースに出力する DatabaseItemWriter は、 ユニバーサルDAO を使用する。 このため、 詳細は、 ユニバーサルDAO を参照しアノテーションを設定すること。 - JOB定義
- Chunkとしてステップを定義する。
- readerには、 fileItemReader を設定する。
- writerには、 databaseItemWriter を設定する。
<!-- id及びnextは適宜変更すること --> <step id="extract" next="validation"> <listeners> <!-- リスナーの設定は省略 --> </listeners> <!-- item-countは適宜変更すること --> <chunk item-count="3000"> <reader ref="fileItemReader" /> <writer ref="databaseItemWriter" /> </chunk> </step>
補足
fileItemReader は、 データバインド を使用してファイルを読み込む。 ファイルの行番号については、 入力ファイルとワークテーブルに対応したJava Beansの作成 に従って作成することで自動的に保持される。 詳細は、 ファイルのデータの論理行番号を取得する を参照
databaseItemWriter は、 ユニバーサルDAO を使用してワークテーブルにデータを登録する。
- ETL用JOB設定ファイル
JOB定義のステップ名(step id)に対応したキーに対して、以下の設定値を持つオブジェクトを設定する。
キー 設定する値 type file2dbを固定で設定する。bean 入力ファイルとワークテーブルに対応したJava Beans の完全修飾名を設定する。 fileName 入力ファイル名を設定する。
入力ファイルの配置ディレクトリは、 ETL用環境設定ファイルを作成する を参照。
- 設定例
"extract": { "type": "file2db", "bean": "sample.Sample", "fileName": "sample.csv" }
- メッセージの定義
- FileItemReader は、取り込み対象のファイルが存在しない場合例外を送出する。 例外に設定するメッセージは、 メッセージ管理 から取得するため、メッセージの設定が必要となる。 詳細は、 ETLが使用するメッセージを定義する を参照。
4.4.6. Extractフェーズ(SQL*Loader版)を使用する¶
SQL*Loaderを使用したExtractフェーズの実装と設定について解説する。
補足
ワークテーブルの内容を事前に削除する必要がある場合は、SQL*Loaderの設定にてtruncateを実施すると良い。 詳細は、Oracle社のマニュアルを参照。
補足
JOB定義及びETL用JOB設定ファイルは、 JOB定義ファイルとETL用JOB設定ファイルを作成する の Oracle SQL*Loaderを使用したファイル取り込みテンプレート をダウンロードし編集すると良い。
- 入力ファイルとワークテーブルに対応したJava Beansの作成
入力ファイルとワークテーブルに対応したJava Beansを以下のルールに従い作成する。
行番号を保持する属性 ワークテーブルの設計について で説明したように、ワークテーブルには行番号を必ず保持させる。 このため、ワークテーブルに対応したJava Beansにも行番号を保持するための属性を定義する。
なお、行番号をもつ属性の追加は、 WorkItem を継承して実現すること。 WorkItem を継承していない場合、後続のフェーズが実行できなくなるため注意すること。
入力ファイルのレイアウトを定義 データバインド を参照しファイルのレイアウト定義を表すアノテーションを設定する。
SqlLoaderBatchlet では使用しないが、SQL*Loader用のコントロールファイルを自動生成する際に使用する。 詳細は、 コントロールファイルの作成 を参照。
ワークテーブルのテーブルに関する定義 ユニバーサルDAO を参照し、ワークテーブルの定義を表すアノテーションを設定する。
SqlLoaderBatchlet では使用しないが、 バリデーション 時に使用するため設定が必要となる。
また、SQL*Loader用のコントロールファイルを自動生成する際に使用する。 詳細は、 コントロールファイルの作成 を参照。
- JOB定義
- batchletとしてステップを定義する。
- batchletクラスには、 sqlLoaderBatchlet を設定する。
<!-- id及びnextは適宜変更すること --> <step id="extract" next="validation"> <listeners> <!-- リスナーの設定は省略 --> </listeners> <batchlet ref="sqlLoaderBatchlet" /> </step>
- ETL用JOB設定ファイル
- Extract(Chunk版)のETL用JOB設定ファイル を参照。
- 接続先データベースの設定
コンポーネント設定ファイル に以下の設定を行う。
<component name="sqlLoaderConfig" class="nablarch.etl.SqlLoaderConfig"> <!-- 接続ユーザ --> <property name="userName" value="${nablarch.db.user}" /> <!-- 接続パスワード --> <property name="password" value="${nablarch.db.password}" /> <!-- 接続先データベース名 --> <property name="databaseName" value="${sqlloader.database}" /> </component>
- ポイント
- コンポーネント名は
sqlLoaderConfigとする。 - 設定するクラスは、 nablarch.etl.SqlLoaderConfig とする。
- 接続先データベースの情報は、環境毎に変わる可能性があるため 環境設定ファイル に定義し、 環境設定ファイルの値を参照 するとよい。
- コンポーネント名は
- コントロールファイルの作成
コントロールファイルは、 ETL Mavenプラグイン を使用して 入力ファイルとワークテーブルに対応したJava Beans から自動生成できる。 ワークテーブルへの行番号の挿入に関しても、 ETL Mavenプラグイン を使用した場合は、 入力ファイルとワークテーブルに対応したJava Beans の定義を元に自動的に設定される。
ETL Mavenプラグイン を使用せずにコントロールファイルを作成する場合は、ワークテーブルに対する行番号の設定を必ず行うこと。
- SQL*Loaderに関わるファイルについて
SQL*Loaderに関わるファイルの命名ルールは以下の通り。 なお、これらのファイルの配置ディレクトリの設定は、 ETL用環境設定ファイルを作成する を参照。
ファイルの種類 ファイル名 コントロールファイル ファイル名は、 入力ファイルとワークテーブルに対応したJava Beans のクラス名 +
.ctl例えば、クラス名が
sample.SampleFileの場合、コントロールファイルの名前はSampleFile.ctlとなる。不良ファイル ファイル名は、 入力ファイルとワークテーブルに対応したJava Beans のクラス名 +
.bad例えば、クラス名が
sample.SampleFileの場合、コントロールファイルの名前はSampleFile.badとなる。ログファイル ファイル名は、 入力ファイルとワークテーブルに対応したJava Beans のクラス名 +
.log例えば、クラス名が
sample.SampleFileの場合、コントロールファイルの名前はSampleFile.logとなる。- メッセージの定義
- SqlLoaderBatchlet は、取り込み対象のファイルが存在しない場合例外を送出する。 例外に設定するメッセージは、 メッセージ管理 から取得するため、メッセージの設定が必要となる。 詳細は、 ETLが使用するメッセージを定義する を参照。
4.4.7. Transformフェーズでバリデーションを行う¶
Transformフェーズで行うバリデーションの実装と設定について解説する。
補足
JOB定義及びETL用JOB設定ファイルは、 JOB定義ファイルとETL用JOB設定ファイルを作成する の JSR352のChunkを使用したファイル取り込みのテンプレート をダウンロードし編集すると良い。
- バリデーションエラーとなったレコードを格納するテーブルを定義する
- バリデーションエラーとなったレコードはワークテーブルからエラーテーブルに移送(ワークテーブルからは削除)される。 このため、ワークテーブルと全く同じレイアウトでエラーレコード格納用テーブルを定義する。
- エラーテーブルに対応したEntityを作成する
エラーレコード格納用のテーブルは、ワークテーブルと全く同じレイアウトとなるため、 Extract(Chunk版) や Extract(SQL*Loader版) で作成したワークテーブルに対応するJava Beansを継承して作成すると良い。
継承した場合、Entityであることを表す Entity アノテーションと、 テーブル名を設定する Table アノテーションを設定する。
- JOB定義
- batchletとしてステップを定義する。
- batchletクラスには、 validationBatchlet を設定する。
progressLogOutputIntervalプロパティに、進捗ログの出力間隔を設定する。指定しない場合のデフォルトは1000。
<!-- id及びnextは適宜変更すること --> <step id="validation" next="load"> <listeners> <!-- リスナーの設定は省略 --> </listeners> <batchlet ref="validationBatchlet"> <properties> <property name="progressLogOutputInterval" value="5000" /> </properties> </batchlet> </step>
- ETL用JOB設定ファイル
JOB定義のステップ名(step id)に対応したキーに対して、以下の設定値を持つオブジェクトを設定する。
キー 設定する値 type validationを固定で設定する。bean Extract(chunk版) や Extract(SQL*Loader版) で作成したワークテーブルに対応するJava Beansの完全修飾名を設定する。 errorEntity エラーテーブルに対応したEntity の完全修飾名を設定する。 mode バリデーションエラー発生時のJOBの継続モードを設定する。
modeを設定しなかった場合は、デフォルトの動作としてABORTとなる。- ABORT
ABORTを設定した場合、バリデーションエラーが発生すると後続のステップは実行せずに EtlJobAbortedException を送出しJOBを異常終了する。 なお、異常終了のタイミングは全てのレコードのバリデーション後となる。- CONTINUE
CONTINUEを設定した場合、バリデーションエラーが発生しても後続のステップが実行される。なお、JOBの Exit Status には、
WARNINGを設定する。WARNINGの詳細は、 バッチアプリケーションの終了コード を参照
errorLimit 許容するエラー数を設定する。
modeの設定に関係なく、許容するエラー数を超えるバリデーションエラーが発生したタイミングで、 EtlJobAbortedException を送出しJOBを異常終了する。なお設定を省略した場合や負数を設定した場合は、本設定は無効となる。
- 設定例
"validation": { "type": "validation", "bean": "com.nablarch.example.app.batch.ee.dto.ZipCodeDto", "errorEntity": "com.nablarch.example.app.batch.ee.dto.ZipCodeErrorEntity", "mode": "ABORT", "errorLimit" : 100 }
- メッセージの定義
- ValidationBatchlet は、バリデーションエラーが発生したことをログに出力する。 ログに出力する文言は、 メッセージ管理 から取得するため、メッセージの設定が必要となる。 詳細は、 ETLが使用するメッセージを定義する を参照。
4.4.8. Loadフェーズでファイルにデータを出力する¶
Loadフェーズで行うファイル出力の実装と設定について解説する。
補足
JOB定義及びETL用JOB設定ファイルは、 JOB定義ファイルとETL用JOB設定ファイルを作成する の ファイル出力のテンプレート をダウンロードし編集すると良い。
- 出力先ファイルに対応したJava Beansの作成
出力先ファイルに対応したJava Beansを作成する。
レイアウト定義は、 データバインド を参照しアノテーションを設定する。
- 編集用SQLの作成
ファイルに出力するデータを取得するSQLを作成する。なお、編集処理が必要な場合には、このSQLにて関数などを用いて実施する。
作成したSQLは、以下のファイルに保存する。SQLファイル内でのSQLの記述方法は、 SQLをファイルで管理する を参照。 なお、本機能では外部から条件などのパラメータを与えることは出来ない。
- ファイル名は、 出力先ファイルに対応したJava Beans のクラス名 +
.sql - ファイルは、クラスパス配下の 出力先ファイルに対応したJava Beans のパッケージと同じディレクトリに配置する
例えば、 出力先ファイルに対応したJava Beans の完全修飾名が、
nablarch.sample.SampleFileDtoの場合、 ファイルの配置先はクラスパス配下のnablarch/sampleディレクトリ配下となる。 ファイル名は、SampleFileDto.sqlとなる。SQLファイル内に定義するSQLIDは任意の値を指定する。SQLIDは ETL用JOB設定ファイル で使用する。
- ファイル名は、 出力先ファイルに対応したJava Beans のクラス名 +
- JOB定義
- Chunkとしてステップを定義する。
- readerには、 databaseItemReader を設定する。
- writerには、 fileItemWriter を設定する。
<!-- idは適宜変更すること load後に後続のステップを実行したい場合は、nextを定義し次のステップを実行すること --> <step id="load"> <listeners> <!-- リスナーの設定は省略 --> </listeners> <!-- item-countは適宜変更すること --> <chunk item-count="3000"> <reader ref="databaseItemReader" /> <writer ref="fileItemWriter" /> </chunk> </step>
- ETL用JOB設定ファイル
JOB定義のステップ名(step id)に対応したキーに対して、以下の設定値を持つオブジェクトを設定する。
キー 設定する値 type db2fileを固定で設定する。bean 出力先ファイルに対応したJava Beans の完全修飾名を設定する。 fileName 出力するファイルのファイル名を設定する。
ファイルの出力先ディレクトリは、 ETL用環境設定ファイルを作成する を参照。
sqlId 編集用のSQL作成 で設定したSQLIDを設定する。 - 設定例
"load": { "type": "db2file", "bean": "sample.SampleDto", "fileName": "output.csv", "sqlId": "SELECT_ALL" }
- メッセージの定義
- FileItemWriter は、出力先ファイルを開けない場合例外を送出する。 例外に設定するメッセージは、 メッセージ管理 から取得するため、メッセージの設定が必要となる。 詳細は、 ETLが使用するメッセージを定義する を参照。
4.4.9. Loadフェーズでデータベースのデータの洗い替えを行う¶
Loadフェーズで行うデータベース上のテーブルデータの洗い替えの実装と設定について解説する。
補足
JOB定義及びETL用JOB設定ファイルは、 JOB定義ファイルとETL用JOB設定ファイルを作成する の Loadフェーズで洗い替えモードを使用する場合のテンプレート をダウンロードし編集すると良い。
- 洗い替え対象テーブルに対応したEntityを作成する
洗い替え対象テーブルの定義を表すEntityを作成する。
テーブルの定義は、 ユニバーサルDAO を参照しアノテーションを設定する。
- 編集用SQLの作成
データベースのテーブルに登録するデータを取得するSQLを作成する。なお、編集処理が必要な場合には、このSQLにて関数などを用いて実施する。
作成したSQLは、以下のファイルに保存する。SQLファイル内でのSQLの記述方法は、 SQLをファイルで管理する を参照。 なお、本機能では外部から条件などのパラメータを与えることは出来ない。
- ファイル名は、 洗い替え対象テーブルに対応したEntity のクラス名 +
.sql - ファイルは、クラスパス配下の 洗い替え対象テーブルに対応したEntity のパッケージと同じディレクトリに配置する
例えば、 洗い替え対象テーブルに対応したEntity の完全修飾名が、
nablarch.sample.SampleEntityの場合、 ファイルの配置先はクラスパス配下のnablarch/sampleディレクトリ配下となる。 ファイル名は、SampleEntity.sqlとなる。SQLファイル内に定義するSQLIDは任意の値を指定する。SQLIDは ETL用JOB設定ファイル で使用する。
- ファイル名は、 洗い替え対象テーブルに対応したEntity のクラス名 +
- JOB定義
- batchletとしてステップを定義する。
- batchletクラスには、 deleteInsertBatchlet を設定する。
<!-- idは適宜変更すること load後に後続のステップを実行したい場合は、nextを定義し次のステップを実行すること --> <step id="load"> <listeners> <!-- リスナーの設定は省略 --> </listeners> <batchlet ref="deleteInsertBatchlet" /> </step>
- ETL用JOB設定ファイル
JOB定義のステップ名(step id)に対応したキーに対して、以下の設定値を持つオブジェクトを設定する。
キー 設定する値 type db2dbを固定で設定する。bean 洗い替え対象テーブルに対応したEntity の完全修飾名を設定する。 sqlId 編集用のSQLの作成 で設定したSQLIDを設定する。 insertMode データの登録(INSERT)時に使用するモードを設定する。設定を省略した場合は
NORMALモードで動作する。- NORMAL
NORMALを設定した場合は、ヒント句の設定などは行わずデータの登録処理を行う。- ORACLE_DIRECT_PATH
ORACLE_DIRECT_PATHを設定した場合、ヒント句を自動的に設定しダイレクトパスインサートモードにてデータの登録処理を行う。 (Oracleデータベースの場合のみ有効)
updateSize.size コミット間隔を設定する。
コミット間隔を設定すると、INSERT~SELECTの実行をコミット間隔毎に分割して行う。 なお、分割してSQLを実行するために、 ワークテーブルに定義された行番号カラム を使用する。 このため、 編集用のSQL には、行番号カラムを使用した範囲検索の条件を必ず設定する必要がある。 付与する条件は、
where line_number between ? and ?となる。省略した場合(省略した場合は、
updateSizeキー自体の定義を行わない)は、1回のINSERT~SELECTで全データの登録処理を行う。本設定値を設定した場合は、
updateSize.beanも設定すること。updateSize.bean Extractフェーズ(Chunk版) や Extractフェーズ(SQL*Loader版) で作成した ワークテーブルに対応したJava Beansの完全修飾名を設定する。
ここで設定したクラス名は、入力テーブル内の行番号カラムの中で最も大きい値を取得する際に、テーブル名を取得するために使用する。
- 設定例
"load": { "type": "db2db", "bean": "sample.SampleEntity", "sqlId": "SELECT_ALL" "insertMode" : "NORMAL" "updateSize": { "size": 5000 "bean": "sample.SampleWorkEntity" } }
4.4.10. Loadフェーズでデータベースのデータのマージを行う¶
Loadフェーズで行うデータベース上のデータのマージ処理の実装と設定について解説する。
補足
JOB定義及びETL用JOB設定ファイルは、 JOB定義ファイルとETL用JOB設定ファイルを作成する の Loadフェーズでマージモードを使用する場合のテンプレート をダウンロードし編集すると良い。
- マージ対象テーブルに対応したEntityを作成する
マージ対象テーブルの定義を表すEntityを作成する。
テーブルの定義は、 ユニバーサルDAO を参照しアノテーションを設定する。
- 編集用SQLの作成
データベースのテーブルにマージするデータを取得するSQLを作成する。なお、編集処理が必要な場合には、このSQLにて関数などを用いて実施する。
作成したSQLは、以下のファイルに保存する。SQLファイル内でのSQLの記述方法は、 SQLをファイルで管理する を参照。 なお、本機能では外部から条件などのパラメータを与えることは出来ない。
- ファイル名は、 マージ対象テーブルに対応したEntity のクラス名 +
.sql - ファイルは、クラスパス配下の マージ対象テーブルに対応したEntity のパッケージと同じディレクトリに配置する
例えば、 マージ対象テーブルに対応したEntity の完全修飾名が、
nablarch.sample.SampleEntityの場合、 ファイルの配置先はクラスパス配下のnablarch/sampleディレクトリ配下となる。 ファイル名は、SampleEntity.sqlとなる。SQLファイル内に定義するSQLIDは任意の値を指定する。SQLIDは ETL用JOB設定ファイル で使用する。
- ファイル名は、 マージ対象テーブルに対応したEntity のクラス名 +
- JOB定義
- batchletとしてステップを定義する。
- batchletクラスには、 mergeBatchlet を設定する。
<!-- idは適宜変更すること load後に後続のステップを実行したい場合は、nextを定義し次のステップを実行すること --> <step id="load"> <listeners> <!-- リスナーの設定は省略 --> </listeners> <batchlet ref="mergeBatchlet" /> </step>
- ETL用JOB設定ファイル
JOB定義のステップ名(step id)に対応したキーに対して、以下の設定値を持つオブジェクトを設定する。
キー 設定する値 type db2dbを固定で設定する。bean マージ対象テーブルに対応したEntity の完全修飾名を設定する。 sqlId 編集用のSQL作成 で設定したSQLIDを設定する。 mergeOnColumns マージ処理を行う際に、出力対象テーブルにデータが存在しているかをチェックする際に使用するカラム名を配列オブジェクトとして設定する。 updateSize.size コミット間隔を設定する。
コミット間隔を設定すると、マージ処理の実行をコミット間隔毎に分割して行う。 なお、分割してSQLを実行するために、 ワークテーブルに定義された行番号カラム を使用する。 このため、 編集用のSQL には、行番号カラムを使用した範囲検索の条件を必ず設定する必要がある。 付与する条件は、
where line_number between ? and ?となる。省略した場合(省略した場合は、
updateSizeキー自体の定義を行わない)は、1回のマージ実行で全データの登録処理を行う。本設定値を設定した場合は、
updateSize.beanも設定すること。updateSize.bean Extractフェーズ(Chunk版) や Extractフェーズ(SQL*Loader版) で作成した ワークテーブルに対応したJava Beansの完全修飾名を設定する。
ここで設定したクラス名は、入力テーブル内の行番号カラムの中で最も大きい値を取得する際に、テーブル名を取得するために使用する。
- 設定例
"load": { "type": "db2db", "bean": "sample.SampleEntity", "sqlId": "SELECT_ALL", "mergeOnColumns": [ "key1" ], "updateSize": { "size": 5000, "bean": "sample.SampleWorkEntity" } }
4.4.11. Loadフェーズでデータベースへの登録を行う¶
Loadフェーズで行うデータベースへの登録の実装と設定について解説する。
補足
JOB定義及びETL用JOB設定ファイルは、 JOB定義ファイルとETL用JOB設定ファイルを作成する の JSR352のChunkを使用したファイル取り込みのテンプレート をダウンロードし編集すると良い。
- 登録対象テーブルに対応したEntityを作成する
登録対象テーブルの定義を表すEntityを作成する。
テーブルの定義は、 ユニバーサルDAO を参照しアノテーションを設定する。
- 登録用SQLの作成
データベースのテーブルに登録するデータを取得するSQLを作成する。なお、編集処理が必要な場合には、このSQLにて関数などを用いて実施する。
作成したSQLは、以下のファイルに保存する。SQLファイル内でのSQLの記述方法は、 SQLをファイルで管理する を参照。 なお、本機能では外部から条件などのパラメータを与えることは出来ない。
- ファイル名は、 登録対象テーブルに対応したEntity のクラス名 +
.sql - ファイルは、クラスパス配下の 登録対象テーブルに対応したEntity のパッケージと同じディレクトリに配置する
例えば、 登録対象テーブルに対応したEntity の完全修飾名が、
nablarch.sample.SampleEntityの場合、 ファイルの配置先はクラスパス配下のnablarch/sampleディレクトリ配下となる。 ファイル名は、SampleEntity.sqlとなる。SQLファイル内に定義するSQLIDは任意の値を指定する。SQLIDは ETL用JOB設定ファイル で使用する。
- ファイル名は、 登録対象テーブルに対応したEntity のクラス名 +
- JOB定義
- Chunkとしてステップを定義する。
- readerには、 databaseItemReader を設定する。
- writerには、 databaseItemWriter を設定する。
<!-- idは適宜変更すること load後に後続のステップを実行したい場合は、nextを定義し次のステップを実行すること --> <step id="load"> <listeners> <!-- リスナーの設定は省略 --> </listeners> <!-- item-countは適宜変更すること --> <chunk item-count="3000"> <reader ref="databaseItemReader" /> <writer ref="databaseItemWriter" /> </chunk> </step>
- ETL用JOB設定ファイル
JOB定義のステップ名(step id)に対応したキーに対して、以下の設定値を持つオブジェクトを設定する。
キー 設定する値 type db2dbを固定で設定する。bean 登録対象テーブルに対応したEntity の完全修飾名を設定する。 sqlId 登録用のSQL作成 で設定したSQLIDを設定する。 - 設定例
"extract": { "type": "db2db", "bean": "sample.Sample", "sqlId": "SELECT_ALL" }
4.4.12. ETLが使用するメッセージを定義する¶
本機能では、 メッセージ管理 から以下のメッセージを取得する。 このため、事前に メッセージ管理 の設定に従いメッセージを定義すること。
- 必要なメッセージ
メッセージID 説明 nablarch.etl.input-file-not-found Extract(SQL*Loader版) 及び Extract(Chunk版) で入力ファイルが存在しない場合の例外メッセージとして使用する。
メッセージのプレースホルダ(添字:0)には、存在しない(読み込めない)入力ファイルのパスが設定される。
nablarch.etl.invalid-output-file-path ファイル出力 で出力先ファイルが開けない場合の例外メッセージとして使用する。
メッセージのプレースホルダ(添字:0)には、開けないファイルのパスが設定される。
nablarch.etl.validation-error バリデーション でバリデーションエラーが発生したことをログに出力する際のメッセージとして使用する。 - 定義例
nablarch.etl.input-file-not-found=入力ファイルが存在しません。外部からファイルを受信できているか、ディレクトリやファイルの権限は正しいかを確認してください。入力ファイル=[{0}] nablarch.etl.invalid-output-file-path=出力ファイルパスが正しくありません。ディレクトリが存在しているか、権限が正しいかを確認してください。出力ファイルパス=[{0}] nablarch.etl.validation-error=入力ファイルのバリデーションでエラーが発生しました。入力ファイルが正しいかなどを相手先システムに確認してください。
4.5. 拡張例¶
4.5.1. ETL用JOB設定ファイルを配置するディレクトリのパスを変更する¶
ETL用JOB設定ファイルを配置するディレクトリのパスを変更したい場合は、コンポーネント設定ファイルに設定を行う。
設定例を以下に示す。
<component name="etlConfigLoader" class="nablarch.etl.config.JsonConfigLoader"> <property name="configBasePath" value="classpath:META-INF/sample" /> </component>
- ポイント
- コンポーネント名は、
etlConfigLoaderとすること。 - JsonConfigLoader の
configBasePathプロパティにパスを設定すること。
- コンポーネント名は、
| [1] | ファイルの内容が不正とは、数値項目に非数値が設定されていた場合や、許容する桁数よりも大きい桁数の値が設定されていた場合のことを指す。 |