3. ETL¶
目次
JSR352に準拠したバッチアプリケーション 上で動作するETL(Extract/Transform/Load)機能を提供する。
ETLとは Extract 、 Transform 、 Load の略であり、以下の一連の処理を行う機能である。
| Extract: | 外部データの抽出 |
|---|---|
| Transform: | 抽出したデータの検証・変換 |
| Load: | 変換したデータのデータベースやファイルへの出力 |
ETLを使うことで以下のメリットが得られる。
- インタフェースファイルの取り込みや作成処理を、設定ファイルとSQL、Beanの作成のみで実現できる。
- JSR352に準拠したバッチアプリケーション のBatchletやChunkステップとして各フェーズが提供されている。 このため、プロジェクト側で実装の差し替えや追加が容易に行える。
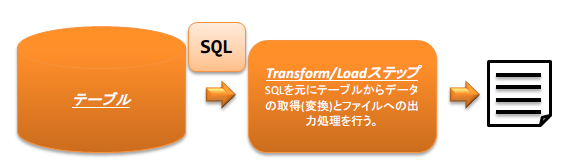
以下にETLの処理イメージを示す。
- ファイルの内容をデータベースへ登録

- データベースの内容をファイルへ出力
重要
ETLを使用したバッチアプリケーションの実例は、Exampleアプリケーション の以下のジョブを参照。
- etl-zip-code-csv-to-db-insert-batchlet
- etl-zip-code-csv-to-db-chunk
- etl-zip-code-db-to-csv-chunk
3.1. モジュール一覧¶
<dependency>
<groupId>com.nablarch.framework</groupId>
<artifactId>nablarch-etl</artifactId>
</dependency>
3.2. ETLの各フェーズの仕様¶
3.2.1. Extractフェーズ¶
Extractフェーズでは、ファイルの内容をデータベース上のワークテーブルに取り込む。
- ワークテーブルの設計時の注意点
ワークテーブルはファイルの内容が不正であった場合でも、ファイルの内容を登録出来るように以下の定義とする必要がある。 ※ファイルの内容が不正とは、数値項目に非数値が設定されていた場合などのことを指す。
- 全てのカラムのデータ型を可変長の文字列型とする
- データ長はデータベースで定義可能な最も大きい値とする
- データのロード方法の選択
次の中からデータのロード方法を選択する。
なお、使用するデータベース付属のデータロードツールなどを使用することで、高速にデータをロード出来るのであればプロジェクト独自の実装を追加するとよい。
- Oracle SQL*Loaderを使用したデータのロード
Oracleデータベースに付属のSQL*Loaderユーティリティを用いたロード処理を行う。
JOB定義ファイルのExtractフェーズに対応するステップ定義に sqlLoaderBatchlet を設定することで、SQL*Loaderを使用したロードが行われる。
- JSR352 のChunkステップを使用したデータのロード
JSR352 のChunkステップを使用して、ファイルからデータを読み込み順次ワークテーブルに登録(INSERT)を行う。
JOB定義ファイルのExtractフェーズに対応するステップ定義は、以下のChunkステップを定義する。
- readerには、 fileItemReader を登録する
- writerには、 databaseItemWriter を登録する
ちなみに
ワークテーブルをクリーニングする必要がある場合には、データのロード処理の前にクリーニングのステップを配置すること。 クリーニング処理を使用する場合には、JOB定義ファイルのクリーニングに対応するステップ定義に tableCleaningBatchlet を設定する。
ちなみに
ワークテーブルにデータを登録するためのINSERT文は、ワークテーブルに対応したBeanオブジェクト(Entity)から自動生成される。
3.2.2. Transformフェーズ¶
Transformフェーズでは、Extractフェーズでワークテーブルに取り込んだファイルの内容のバリデーションとデータの変換(編集)処理を行う。
データの変換(編集)処理は、SQL文のSELECT句によって実現する。 例えば、SQLファンクションを呼び出したり他のテーブルと結合するなどして、データの変換処理を実現する。
ちなみに
データの変換処理は、LoadフェーズのSQL文実行タイミングで実施される。
- データのバリデーション
データのバリデーションを行う場合は、 JOB定義ファイルにバリデーション用のステップを定義する。 バリデーションステップの定義には、 validationBatchlet を登録する。
バリデーションエラーが発生した場合、そのレコードの情報はワークテーブルと全く同じレイアウトのエラーテーブルに移動される。 エラーの情報(エラー内容やエラーが発生した項目名)はアプリケーションログに出力される。
バリデーションエラーが発生した場合の動作を次から選択できる。
アボートモード(デフォルト): バリデーションエラーが発生した場合、JOBを異常終了する。 継続モード: JOBは終了せずに次のフェーズ(ステップ)に処理が移動する。 ちなみに
上記のモードとは別に、許容するエラー数を設定することができる。 許容するエラー数を設定した場合、モード設定とは関係なく、設定値を超えるバリデーションエラーが発生した時点でJOBは異常終了する。
- データの変換処理
データの変換のために作成するSQLは以下のルールに従うこと。
SELECT句に列挙する項目には、データのロード先テーブルのカラム名を別名として設定する。
ロード先がファイルの場合には、ファイルに対応したBeanオブジェクトのプロパティ名を別名(スネークケースでも可)として設定する必要がある。
SQL文にはパラメータ(バインド変数)を使用しない。
パラメータを使用したい場合には、パラメータを持つ別テーブルを定義して結合するなどして回避すること。
3.2.3. Loadフェーズ¶
Transformフェーズのデータ変換用SQL文を実行し、データをデータベースやファイルに出力する。
- データベース出力
データベース出力用に次のモードを提供する。要件に応じて適切なモードを選択すること。
洗い替えモード: 既存のデータを全て削除後に登録処理を行う。
JOB定義ファイルの該当ステップには、 deleteInsertBatchlet を設定する。
マージモード: 既存のデータが存在している場合には更新処理を、データが存在していない場合には、追加処理を行う。
JOB定義ファイルの該当ステップには、 mergeBatchlet を設定する。
大量データを一括で登録(更新)した場合、UNDO表領域(Oracleの場合)が不足する可能性があるため、分割実行する機能を提供する。 分割実行する場合には、一度に実行する単位と実行対象を取得するための条件を設定する。
データの変換がSQLでは実施できない場合(Javaのライブラリを使用する等)、以下のChunkステップをJOB定義ファイルの該当ステップに定義する。
- readerには、 databaseItemReader を登録する
- writerには、 databaseItemWriter を登録する
- processorには、プロジェクト側で独自にデータ変換処理を実装した ItemProcessor を登録する
Oracleデータベースの場合には、ダイレクトパスインサートモードを選択することで、一括でデータを登録することもできる。(洗い替えモードの場合のみ)
- ファイル出力
データをファイルに出力する場合は、JOB定義ファイルの該当ステップに以下のChunkステップを定義する。
- readerには、 databaseItemReader を登録する
- writerには、 fileItemWriter を登録する
3.3. 使用方法¶
3.3.1. ETL JOBを実行するための設定を行う¶
ETL JOBを実行するためには以下の設定ファイルが必要となる。
- JOB定義ファイル
ETLジョブのジョブ構成を定義するファイル。
詳細は、 JSR352に準拠したバッチアプリケーション 及び JSR352 Specification を参照すること。
- ETL用設定ファイル
ETLの共通設定及びJOB毎の設定を行う設定ファイル。
JSON形式で作成する必要がある。
詳細は、 ETL用設定ファイルを作成する を参照。
3.3.2. ETL用設定ファイルを作成する¶
ETL用設定ファイルは、システム共通設定部とJOB毎の設定部で構成される。
JOB毎の設定部では、ETLの各フェーズに対応する設定を行う。
JOB毎の設定部は、 JOB ID 及び STEP ID でJOB定義ファイルと紐付いている。
ETL用設定ファイルは、デフォルトではクラスパス配下の META-INF/etl.json となる。
ETL用設定ファイルのパスをデフォルトから変更したい場合は、 ETL用設定ファイルのパスを変更する を参照。
- システム共通設定部
システム共通設定部には、ETL JOB全体で共通となる値の設定を行う。 設定内容は次の例を参照。
{ // ロード対象ファイルの配置ディレクトリのパス "inputFileBasePath": "file/input", // ファイルの出力先ディレクトリのパス "outputFileBasePath": "file/output", //-------------------------------------------------------------------------------- // 以下の2項目はOracle SQL*Loaderを使用する場合のみ必要 //-------------------------------------------------------------------------------- // SQL*Loaderのコントロールファイル配置ディレクトリのパス "sqlLoaderControlFileBasePath": "sqlloader/ctl", // SQL*Loaderが出力するログなどの出力先ディレクトリのパス "sqlLoaderOutputFileBasePath": "sqlloader/log", // JOBの設定 "jobs": { "job1": { }, "job2": { // システム共通設定を上書きする場合には、 // 対象JOB配下に同名のプロパティを定義して上書きを行う。 "inputFileBasePath": "file/job2/input", "outputFileBasePath": "file/job2/output", } } }
- JOB毎の設定部
JOB毎の設定部には、JOB毎に必要となる各フェーズ(Extract/Transform/Load)の設定を行う。
- Extractフェーズの設定
Extractフェーズでは、入力ファイルの内容をワークテーブルに取り込むための設定を行う。 SQL*Loaderを使用せずにデータを取り込む場合には、ワークテーブルのデータをクリーニングするための設定が必要となる。
"jobs": { "sample-job-id": { "steps": { //------------------------------------------------------------ // 明示的にワークテーブルをクリーニングする場合には、 // クリーニング用の設定を行う。 //------------------------------------------------------------ "truncate-step": { // 固定で"truncate"を指定 "type": "truncate", // 削除対象のテーブルに対応するEntityクラスのFQCNを配列で指定する。 "entities": [ "com.nablarch.example.app.batch.ee.dto.ZipCodeDto" ] }, "extract-step": { // 固定で"file2db"を指定 "type": "file2db", // 一時テーブルに対応するBeanを指定 "bean": "com.nablarch.example.app.batch.ee.dto.ZipCodeDto", // 入力データのファイル名を指定 "fileName": "KEN_ALL.CSV" } } } }
- JOB定義ファイル例
上記ETL設定ファイルに対応するJOB定義ファイル例を示す。 なお、以下の設定ファイルには、データベース接続設定などは記載していない。
<job id="sample-job-id" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0"> <!--****************************** SQL*Loaderを使用する場合 ******************************--> <!-- extractフェーズのステップ --> <step id="extract-step"> <batchlet ref="sqlLoaderBatchlet" /> </step> <!--****************************** SQL*Loaderを使用しない場合 ******************************--> <!-- ワークテーブルのクリーニングステップ --> <step id="truncate-step"> <batchlet ref="tableCleaningBatchlet" /> </step> <!-- extractフェーズのステップ --> <step id="extract-step"> <chunk> <reader ref="fileItemReader" /> <writer ref="databaseItemWriter" /> </chunk> </step> </job>
- Transformフェーズの設定
Transformフェーズでは、ワークテーブルに取り込んだ入力ファイルの内容をバリデーションするための設定を行う。
"jobs": { "sample-job-id": { "steps": { "validation-step" : { // 固定で"validation"を指定 "type": "validation", // ワークテーブルに対応したBeanオブジェクトのクラス名をFQCNで設定する。 "bean": "com.nablarch.example.app.batch.ee.dto.ZipCodeDto", // エラーのあったレコードを書き込むためのエラーテーブルに対応した // Beanオブジェクトのクラス名をFQCNで設定する。 "errorEntity": "com.nablarch.example.app.batch.ee.dto.ZipCodeErrorEntity", // エラー発生時に処理を継続する場合には、modeにCONTINUEを設定する。 // 異常終了させる場合には、ABORTを設定する。 "mode": "CONTINUE", // 一定数のエラー発生時にJOBを異常終了させたい場合は、 // errorLimitに許容するエラー件数を指定する。 // 以下のように1000を設定した場合、1001件目のエラーでJOBが異常終了する。 "errorLimit": 1000 } } } }
- JOB定義ファイル例
上記ETL設定ファイルに対応するJOB定義ファイル例を示す。 なお、以下の設定ファイルには、データベース接続設定などは記載していない。
<job id="sample-job-id" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0"> <step id="validation-step"> <batchlet ref="validationBatchlet" /> </step> </job>
- Loadフェーズの設定
Loadフェーズでは、データベースやファイルにデータを出力するための設定を行う。
"jobs": { "sample-job-id": { "steps": { //------------------------------------------------------------ // 洗い替えモードの設定例 //------------------------------------------------------------ "db-output-step": { // 固定で"db2db"を指定 "type": "db2db", // 出力対象テーブルに対応するBeanオブジェクトのクラス名をFQCNで設定する "bean": "com.nablarch.example.app.entity.ZipCodeData", // データの変換用SQLのSQL_IDを設定する "sqlId": "SELECT_ZIPCODE_FROM_WORK", // insertModeを指定する。 // insertModeにORACLE_DIRECT_PATHを指定するとダイレクトパスインサートが使用される。 // insertModeを指定しない場合、デフォルトのNORMALが適用される。 "insertMode": "NORMAL", // 洗い替え時に何件ごとにデータを移送するかとワークテーブルに対応するBeanを指定 // ※insertModeにORACLE_DIRECT_PATHを指定した場合、updateSizeを設定することは出来ない "updateSize": { "size": 200000, "bean": "com.nablarch.example.app.batch.ee.dto.ZipCodeDto" } }, //------------------------------------------------------------ // マージモードの設定例 //------------------------------------------------------------ "merge-step": { // 固定で"db2db"を指定 "type": "db2db", // 出力対象テーブルに対応するBeanオブジェクトのクラス名をFQCNで設定する "bean": "com.nablarch.example.app.entity.ZipCodeData", // データの変換用SQLのSQL_IDを設定する "sqlId": "SELECT_ZIPCODE_FROM_WORK", // MERGEのON句に指定するカラム名を配列で設定する "mergeOnColumns": ["LOCAL_GOVERNMENT_CODE","ZIP_CODE_5DIGIT","ZIP_CODE_7DIGIT"], // MERGE処理中、何件ごとに更新するかとワークテーブルに対応するBeanを指定 "updateSize": { "size": 200000, "bean": "com.nablarch.example.app.batch.ee.dto.ZipCodeDto" } }, //------------------------------------------------------------ // ファイル出力の設定例 //------------------------------------------------------------ "file-output-step": { // 固定で"db2file"を指定 "type": "db2file", // 出力ファイルに対応するBeanオブジェクトのクラス名をFQCNで設定する "bean": "com.nablarch.example.app.batch.ee.dto.ZipCodeDto", // 出力ファイルのファイル名を設定する "fileName": "etl-zip-code-output-chunk.csv", // データの変換用SQLのSQL_IDを設定する "sqlId": "SELECT_ZIPCODE" } } } }
- JOB定義ファイル例
上記ETL設定ファイルに対応するJOB定義ファイル例を示す。 なお、以下の設定ファイルには、データベース接続設定などは記載していない。
<!--********************************************** 洗い替えモード用のステップ定義 **********************************************--> <step id="db-output-step"> <batchlet ref="deleteInsertBatchlet" /> </step> <!--********************************************** マージモード用のステップ定義 **********************************************--> <step id="merge-step"> <batchlet ref="mergeBatchlet" /> </step> <!--********************************************** ファイル出力用のステップ定義 **********************************************--> <step id="file-output-step"> <chunk item-count="1000"> <reader ref="databaseItemReader" /> <writer ref="fileItemWriter" /> </chunk> </step>
3.3.3. ETL用設定ファイルのパスを変更する¶
ETL用設定ファイルのパスを変更する場合は、 JsonConfigLoader にETL用設定ファイルのパスを設定して、 コンポーネント設定ファイルに定義する必要がある。
例を以下に示す。
- ポイント
- コンポーネント名は、
etlConfigLoaderとすること。 configPathプロパティに、ETL用設定ファイルのパスを設定する。
- コンポーネント名は、
<component name="etlConfigLoader" class="nablarch.etl.config.JsonConfigLoader">
<property name="configPath" value="custom.json"/>
</component>
重要
現状、ETL用設定ファイルのパスを複数設定することはできない。 そのため、ETL用の設定は複数のファイルに分割せずに1ファイルにまとめて定義すること。